Kazidomi




Kazidomi is a sustainable e-commerce platform that delivers organic products to 17 countries across Europe. It offers a broad range of expert-selected items – from healthy food, beverages, and beauty products to safe pet food, cleaning supplies, and home decor.
All CustomersWeb App Testing
QAwerk helped Kazidomi deliver new features faster and future-proof their platform through comprehensive web testing. We scrutinized most common user flows and thoroughly tested scenarios directly impacting conversions, ensuring users can easily complete their purchases every single time.
Learn moreAutomated Testing
Our software test engineers helped Kazidomi introduce an effective test automation strategy covering functional, system, UI, and regression tests. With our support, the Kazidomi team could ship site improvements consistently, knowing the builds are stable and without critical bugs.
Learn moreChallenge
Kazidomi turned to QAwerk to strengthen and extend their delivery team with professional QA and test automation engineers. Before our cooperation, they relied on bug reports from their customer care members, which often lacked the necessary details for developers to quickly understand the root cause of the issue.
The partnership with QAwerk aimed at achieving the following results:
- Faster bug fixing. Our task was to complete reports written by the internal team with pre-conditions, steps to reproduce the bug, and other details to save Kazidomi developers’ time and make it crystal clear what went wrong and under what exact circumstances.
- Automated testing. We needed to introduce test automation to reduce the time spent on functional, UI, and regression testing, which in turn leads to faster and smoother delivery of new capabilities to users.
- Improved conversion. QAwerk was responsible for paying utmost attention to the functionality directly impacting conversions. Our goal was to detect all possible conversion killers and ensure the user experiences no hiccups along their journey.
Creating and maintaining test documentation are an integral part of the quality assurance process, and that’s what we did for Kazidomi too. Each feature ready for testing required writing new test cases or updating the existing ones.
Solution
We believe rigorous testing is best achieved with manual and automated testing combined. With test automation, we increased the testing speed and achieved greater coverage. At the same time, manual testing allowed us to have that human touch and explore the platform from the user’s standpoint.
For a web solution like Kazidomi, these types of testing were essential:
- Functional Testing. We put maximum effort into testing most common user actions, such as authorizing, adding products to a cart, modifying cart contents, applying discount codes, among many others. We saw to it that every button, link, and filter serves its purpose and helps the user make a decision.
- Integration Testing. Bugs on a billing page are one of the most widespread conversion killers. Our QA engineers tested the integration with payment systems such as PayPal and Adyen to ensure the checkout is successful and stress-free.
- Cross Browser Testing. Multinational e-commerce platforms like Kazidomi have customers using different browsers on different devices. We made sure the user experience remains high quality regardless of the browser or device used. Automated testing focused on Chrome only.
- UI Testing. A sleek UI is no less important as impeccable app performance as it contributes to that first impression and building brand trust. Our QA team verified if the design implementation matches the requirements specifications.
- Regression Testing. Since Kazidomi ships updates frequently, the need in automating regression testing was apparent. With automated regression in place, bugs were reported timely, allowing Kazidomi developers to fix most critical issues before the release day and stick to their delivery plan.
We wrote 587 test cases from the ground up, among which 284 were automated.
Test Automation
All tests were executed on a server with a new database with no pre-created users or test data. The data was automatically created for each test case right before the test execution. This approach helped keep autotests stable and allowed running them in any order as there were no test data interdependencies. For example, if two test cases rely on the same piece of test data and the first test deletes it as one of the test case steps, the latter test will fail, resulting in a false positive.
Our autotests also contained post-conditions for data cleanup. When new data is generated for every small test case, the size of the data source explodes quite quickly, putting an unnecessary strain on the server. Therefore, each autotest deleted the test data it previously created after successful test execution.
As you can imagine, running 284 autotests simultaneously takes a while, or about 6 hours, to be more precise. To speed things up, we divided all the tests into groups, singling out the smoke group containing about 30 autotests for main product features. Other groups were labeled based on the functionality they checked, for example, “login”, “add to cart”, and “create account.”
These tests were run continuously after each commit to the GitLab repository. If needed, it was also possible to manually launch or skip autotests for a specific group.
Bugs Found
Most bugs we encountered were related to image display, discounts, price calculation, or user authorization.
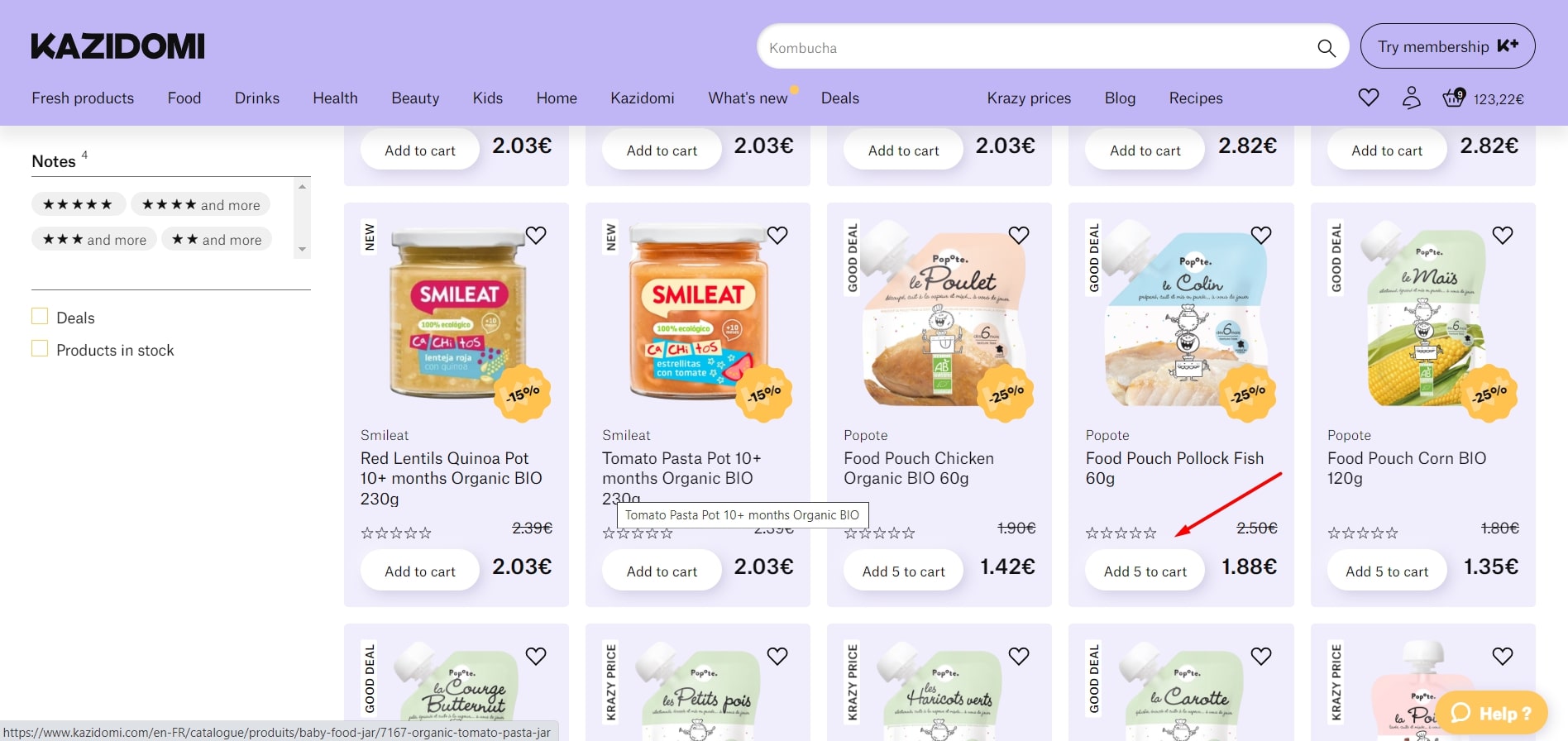
Actual result: “Add 5 to cart” button is active for this product.
Expected result: “Notify me” button should be present on the product tile as it is out of stock.
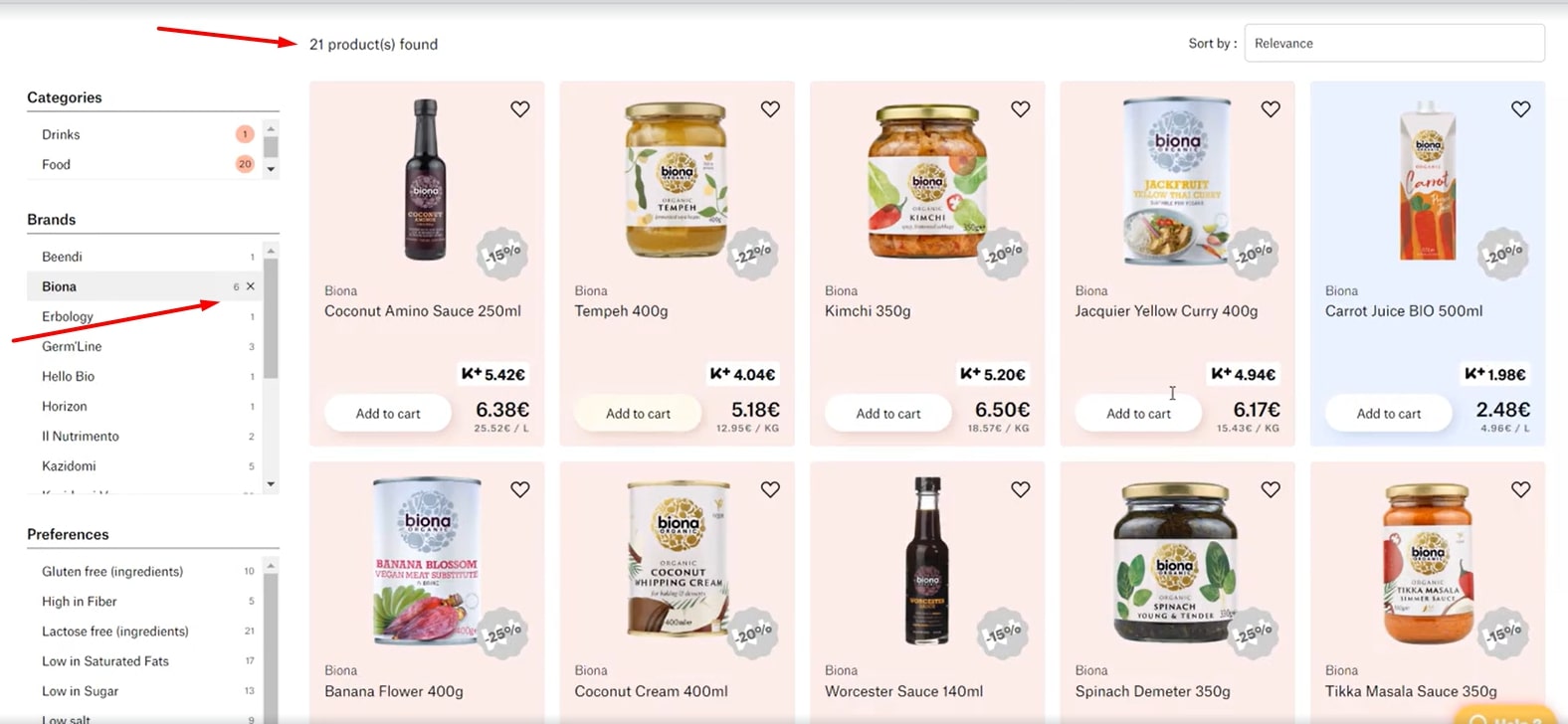
Actual result: Product count in Brands does not match the actual number of products by this brand displayed on page.
Expected result: Product count in Brands matches the actual number of products by this brand displayed on page.
Actual result: -/+ buttons are displayed. Cart icon displays 1 product. Product quantity is displayed correctly after the page reload.
Expected result: Cart is empty. “Add 1 to cart” button is displayed.
Result
Kazidomi’s investment in professional quality assurance brought several benefits. First, we developed a comprehensive suite of test cases serving as a solid foundation for future testing. Another advantage is a faster development cycle through reduced time spent on testing.
Finally, we contributed to improving the product’s quality by detecting critical, medium-severity, and minor bugs before they reached prod, helping Kazidomi continue to delight their users with effortless and satisfying shopping.
Awarded
 LinkedIn News Europe, Number One Startup in Belgium
LinkedIn News Europe, Number One Startup in Belgium
 The Belgian Marketing Awards, Young Belgian Marketing Company of 2021
The Belgian Marketing Awards, Young Belgian Marketing Company of 2021
In Press
Kazidomi, the Brussels-based organic webshop, has acquired its French competitor Smartfooding – including the latter’s organic baby food store Graine de bonne santé
Kazidomi has tripled its sales annually over the past four years. It has more than 20,000 members and is expanding to Holland and Germany.

QAwerk team has been of enormous help in improving the quality of our releases at Kazidomi. They are communicative and highly professional, with a proactive attitude. The automated and manual testing work we did with them was delivered to a high standard, and we’ve become trusted partners.

Looking to step up your e-commerce game?
Let’s talkTools
 Xray
Xray Jira
Jira Symfony Panther
Symfony PantherQAwerk Team Comment

Kateryna
QA automation engineer
While working on the Kazidomi project, I’ve mastered the knowledge of PHP, PHPUnit testing framework, and Symfony Panther library.
I’m grateful to all teammates for working harmoniously and conscientiously. It really felt like we were pursuing one common goal. Even though I’ve primarily communicated with a tech lead who validated the quality of autotests and PM on the client’s side, other members readily shared their expertise and answered our questions regarding the project.


Related in Blog

Complete Website Testing Checklist
Any software development life cycle should involve a testing phase — otherwise, the product already delivered to end users may be full of defects, which will result in a large number of negative reviews, lost customers, and dropoffs. Apparently, websites and web apps aren`t an ...
Read More
How to Write Test Cases: QAwerk’s Comprehensive Guide
Right from the start, we are set to announce that there is no single all-purpose test case type. However, there is an easy-to-follow set of practices and solutions that, when implemented properly, will result in a good one. We’ve put together the test case writing bes...
Read MoreImpressed?
Hire usOther Case Studies
Arctype
Achieved app stability and speeded up software releases by 20% with overnight testing and automation
Keystone
Helped Norway’s #1 study portal improve 8 of their content-heavy websites, which are used by 110 million students annually
Evolv
Increased this digital growth platform’s regression-testing speed by 50%, and ensured the platform runs optimally 24/7